title: "Claude Code vs ChatGPT for Business: What Wins Where" slug: claude-code-vs-chatgpt seo_keyword: "Claude Code vs ChatGPT for business" meta_description: "Claude Code vs ChatGPT for business: after 50+ custom skills and 2.5 years in production. What each actually wins at from daily operator use." og_description: "I use Claude Code, ChatGPT, and Codex daily for B2B GTM work. After building 50+ custom skills and running all three in production, here is what each tool actually wins at and where each falls short." cluster: claude-code-operators author: Victor status: published published_date: 2026-03-24 read_time_minutes: 9 description: "Claude Code vs ChatGPT for Business: What Wins Where" domain: steepworks type: article updated: 2026-03-24
Claude Code vs ChatGPT for Business: What Wins Where
The Real Comparison Is Three Tools, Not Two
Most Claude Code vs ChatGPT for business comparisons pit two chat interfaces against each other on poetry and trivia. The real comparison for operators is three tools -- and they win at different jobs.
Bias disclosure upfront: I run a consulting practice built primarily on Claude Code. My skills library, my knowledge operating system, my client workflows all live in that ecosystem. I have spent 15 years scaling B2B SaaS go-to-market teams -- two exits, sustained 2-3x growth -- and the last 2.5 years building AI-native GTM systems in production. I also use ChatGPT and Codex daily, and I will be honest about where each wins. Factor that in as you read.
Where Claude Code Still Wins -- Context, Taste, and Planning
Persistent Skills That Compound
I have built 50+ custom skills in Claude Code -- persistent, file-aware commands that encode domain expertise into repeatable workflows. Not prompt templates you paste into a chat window. Systems that read your project structure, follow layered rules, and produce consistent output session after session.
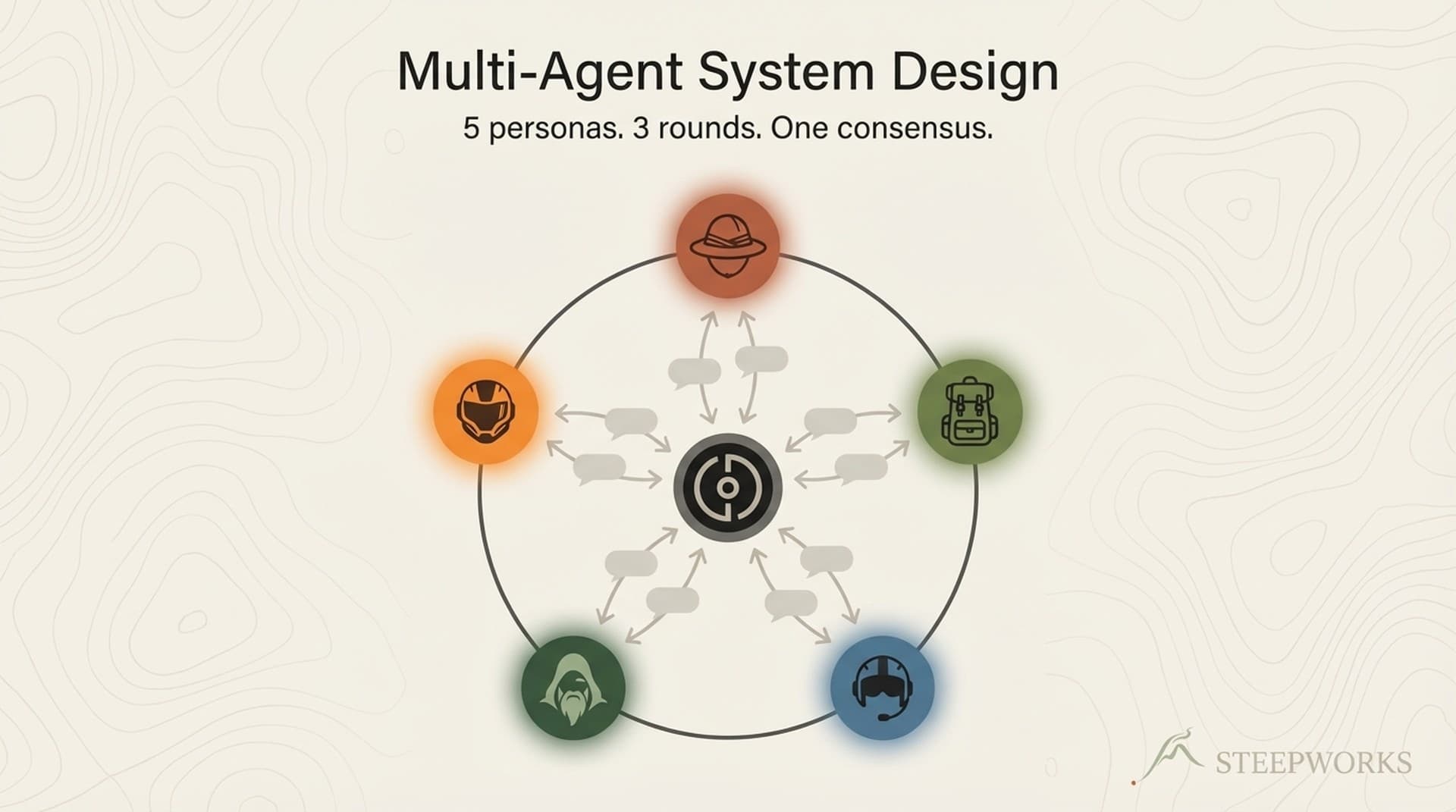
One example worth unpacking: I have a newsletter generation skill that reads brand voice files, checks recently-featured content to avoid repetition, pulls event data from a Supabase database, runs five persona agents through a moderated debate to select and score content, then writes a draft matching the established Beehiiv template. That skill took about three weeks to build and refine. Before it existed, newsletter production cost a full morning of manual curation every week. Now the skill handles the first 80% and I spend thirty minutes editing. Over six months, that is roughly 60 hours reclaimed from a single skill. Multiply across 50+ skills and the compounding math gets interesting.
The key detail: none of that context needs re-explaining. The skill reads its own instructions, checks its own memory, and follows its own rules every time it runs. That is what separates context engineering from prompt engineering -- the system carries the knowledge, not the operator's memory.
Codex can reference parallel skill structures through AGENTS.md. But the depth of integration -- layered rules that load per-folder, session recovery that picks up where you left off, an information pyramid that teaches the model which of your 300+ files to read first and which to skip -- Claude Code's context engineering surface is still ahead.
Editorial Judgment
Last month I gave both Claude Code (Opus) and GPT-5.4 the same prompt: rewrite a weak product positioning paragraph for a client's landing page. Identical brief -- target buyer, pain points, tone. Opus came back with a paragraph that led with the buyer's problem, pulled language from actual customer calls I had loaded as context, and closed with a line that created tension. GPT-5.4 came back with a paragraph that covered the same ground but read like a summary of the brief. Accurate. Complete. Flat.
The difference was not factual. It was editorial. Opus made choices about emphasis and word order that reflected the persuasion goal, not just the information.
That pattern repeats across GTM work -- writing that needs to persuade, research that needs to make judgment calls, plans that need to prioritize one path over another. When I tell Claude Code "this section is weak, rewrite it with more conviction," it shifts tone. It pushes back on vague instructions. GPT-5.4 tends to rephrase the same hedged paragraph with different synonyms.
I do not have a clean benchmark for editorial quality. What I have is eight months of running the same kinds of tasks through both tools and consistently choosing Opus output when the work requires persuasion, framing, or voice. Your mileage depends on your domain.
Planning -- and Why Cross-Model Review Changes It
Opus does planning better than anything else I have used. When I ask both tools to decompose a multi-week content launch into phases, Opus sequences the work so that research feeds the outline, the outline feeds parallel drafts, and the review cycle starts before all drafts are complete -- because it anticipates that review feedback on early drafts will improve later ones. GPT-5.4 produces a linear sequence: research, then outline, then draft, then review. Correct. Misses the overlap.
But here is the more interesting pattern: I do not let Opus review its own plans.
My workflow uses a cross-model review system. Opus generates the plan, then a skill triggers Codex CLI to run an adversarial audit. When Claude Code writes a plan and Claude Code reviews the plan, it agrees with itself. When Codex reviews the plan, it finds different problems -- different assumptions it questions, different risks it flags, different sequencing it challenges. One model's blind spots are not the same as another model's blind spots. Using that asymmetry deliberately is more valuable than picking the "best" model.
You can build skills that work across both platforms. I maintain one canonical skill definition in Claude Code's directory, with thin redirects in the Codex-compatible directory pointing back to the same source. Update once, both platforms see the change. That cross-platform skill layer is what makes the cross-model review possible without duplicating work.
Anthropic's own teams have found similar patterns -- their lawyers built phone tree systems, their marketers generated ad variations, their designers mapped error states. Non-technical teams running agentic workflows is not theoretical. It is happening inside the company that builds the model.
Where Codex Is Closing the Gap
I underestimated Codex. Six months ago I would have said Claude Code was the only serious option for agentic work. GPT-5.4 changed that. (See also: claude md)
On SWE-bench Verified, Claude Opus 4.6 scores 80.8% and GPT-5.2 hits 80.0%. I cite that benchmark not to declare a winner on points but to make a different argument: when scores are this close, the model is not the differentiator. The system you build around the model is. (See also: skill chain)
The async model Codex uses -- queue a task, come back to a result -- fits batch coding work well. Fire off three implementation tasks, go write an email, come back to finished code. For operators who batch their deep work, that workflow matters.
Scoped implementation -- "write this function according to this spec" -- is no longer a Claude Code exclusive. Context engineering, planning, and editorial judgment still favor Claude Code. But the gap on bounded coding tasks has narrowed to the point where I pick based on workflow fit, not model capability.
ChatGPT Wins on Speed
I open ChatGPT more times per day than Claude Code. Claude Code produces more value per session. Different metrics, different winners.
For anything under two minutes -- drafting a reply, brainstorming a subject line, reformatting a paragraph -- ChatGPT's zero-startup-overhead wins. No project loading, no skill initialization. Open the app, get a useful answer.
Voice mode earns a separate mention. I use it for working through article angles on a morning walk, brainstorming subject lines in a school pickup line. Claude does not have an equivalent mobile experience. The friction gap on voice-first thinking is wide.
Picking the Right Tool -- A Decision Framework
When your "codebase" is not just code but a knowledge system with hundreds of markdown files, the interface matters as much as the model. Seeing your folder tree, file contents, and diffs in real time while the agent works is the difference between understanding what changed and trusting a black box. VS Code with Claude Code gives you that visibility. Codex's file navigation is functional but less fluid -- friction that compounds across hundreds of daily interactions.
| The work in front of you | Reach for | Why |
|---|---|---|
| Quick reply, brainstorm, factual lookup | ChatGPT | Speed. Zero setup. |
| Scoped coding task, bug fix, implementation | Codex or Claude Code | Both strong. Codex async model good for batching. |
| Context-heavy planning, multi-phase project | Claude Code (Opus) | Better sequencing, context engineering. |
| Non-coding judgment work (content, strategy, editorial) | Claude Code (Opus) | Stronger editorial choices, easier to shape. |
| Repeatable system (custom skills, persistent workflows) | Claude Code | Skill infrastructure, filesystem access. |
| Stress-testing a plan | Cross-model review (Codex auditing Claude Code) | Different model catches different blind spots. |
| Mobile brainstorming, voice-first thinking | ChatGPT | Voice mode, zero setup. |
A Tiered Adoption Path
Not everyone needs three tools on day one.
Start here: ChatGPT for daily quick tasks, Claude Pro for deeper work. Roughly $40/month. Immediate value, no technical setup.
Add Claude Code: Build 3-5 custom skills for your most repeated workflows. Each skill saves time on every future use. Requires some comfort with markdown files and slash commands, but the compounding payoff is real.
Add cross-model workflows: Make your skills work across Claude Code and Codex. Run cross-model reviews. This is the point where your workflow stops being "use AI tools" and starts being "orchestrate AI tools." Whether you build that layer yourself or bring in help, this is where compounding accelerates.
What I Still Get Wrong
I still default to Claude Code for things ChatGPT would handle faster. Startup overhead on small tasks. Old habits.
I underestimated Codex. The race for scoped tasks is tighter than I expected, and getting tighter every quarter.
I overestimate how fast non-technical operators will adopt any of these tools. 300,000+ businesses now use Claude, and 70% of the Fortune 100. Broad adoption does not mean easy adoption. The learning curve is real for all three.
The tools are converging on raw capability. The divergence is in workflow design -- how you wire them together, what context you feed them, which one you reach for at which moment. That is the skill that compounds.
If you are using one tool today, try adding a second for a week. Not to replace what you have. To see what it wins at that your current tool does not.
Victor Sowers builds AI-native GTM systems at STEEPWORKS. 15 years scaling B2B SaaS, two exits, and 2.5 years of production AI-in-GTM.