title: "Programmatic SEO: 1,000 Pages From Supabase in 25 Hours" slug: 1000-seo-pages-supabase seo_keyword: "programmatic SEO" meta_description: "I turned 2,794 Supabase events into 1,000+ indexable pages in 25 hours. Slug collisions, PostgREST bugs, and a programmatic SEO buildlog." og_description: "Buildlog: turning a Supabase database of 2,794 events into 1,000+ individually indexable pages with JSON-LD, hub pages, and ISR. What worked, what broke, and what Google did with a new domain claiming 1,000 URLs overnight." cluster: content-operations author: Victor status: published published_date: 2026-03-24 read_time_minutes: 12 description: "Programmatic SEO: 1,000 Pages From Supabase in 25 Hours" domain: steepworks type: article updated: 2026-03-24
Programmatic SEO: 1,000 Pages From Supabase in 25 Hours
By Victor Sowers | STEEPWORKS
This is not a programmatic SEO tutorial. It's a buildlog — what happened when I turned a Supabase database of 2,794 events into 1,000+ individually indexable pages on BmoreFamilies.com, each with its own title, venue, date, JSON-LD schema, related events, and newsletter context. Some of it worked. Some of it broke in ways the tutorials never mention.
I'm publishing this because the programmatic SEO guides I found were either theoretical frameworks with no production code, or tutorials that stop at "deploy and watch the traffic roll in." None of them covered what happens when PostgREST silently drops 63 events from your queries, or that recurring events generate slug collisions that break your sitemap, or what Google actually does when a brand-new domain suddenly claims 1,000 pages.
Why I Built This
BmoreFamilies.com is a Baltimore family events directory I built and run. It aggregates events from 313+ sources — museums, parks, libraries, community organizations, sports leagues, performing arts venues — into a Supabase database where they're classified by type, area, age range, and cost.
The site had the richest local family events database in Baltimore, but Google couldn't see any of it. Every event linked out to external source URLs. The sitemap had 8 static pages. Invisible to search, despite sitting on a dataset that answered thousands of long-tail queries — "free museum days Baltimore," "toddler activities near me," "things to do with kids this weekend Baltimore."
The bet was straightforward: if your database already contains unique, structured data that people are searching for, you don't need to write 1,000 blog posts. You generate 1,000 pages from what you already have. Each event is a different combination of title, venue, date, cost, age range, and description. Each page answers a different search query. Not one template with a variable swapped — genuinely different content.
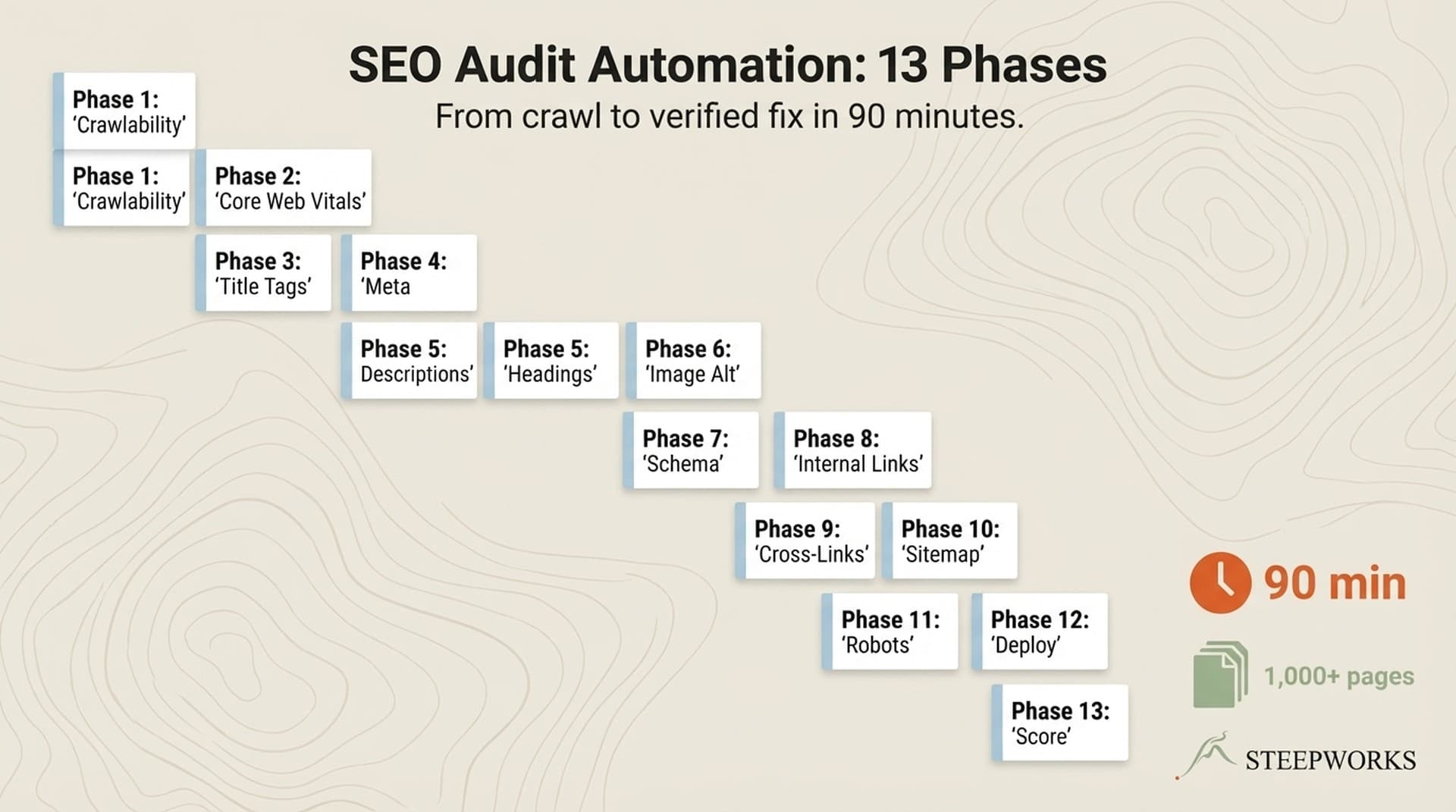
A content writer doing 4 posts a month would need 20+ years to match the keyword coverage this engine produces. I built it in roughly 25 focused hours across 2 days. It now generates new pages automatically as events enter the pipeline. Zero per-page effort.
You can see the live result: bmorefamilies.com/calendar is the entry point. Everything I describe here is running in production.
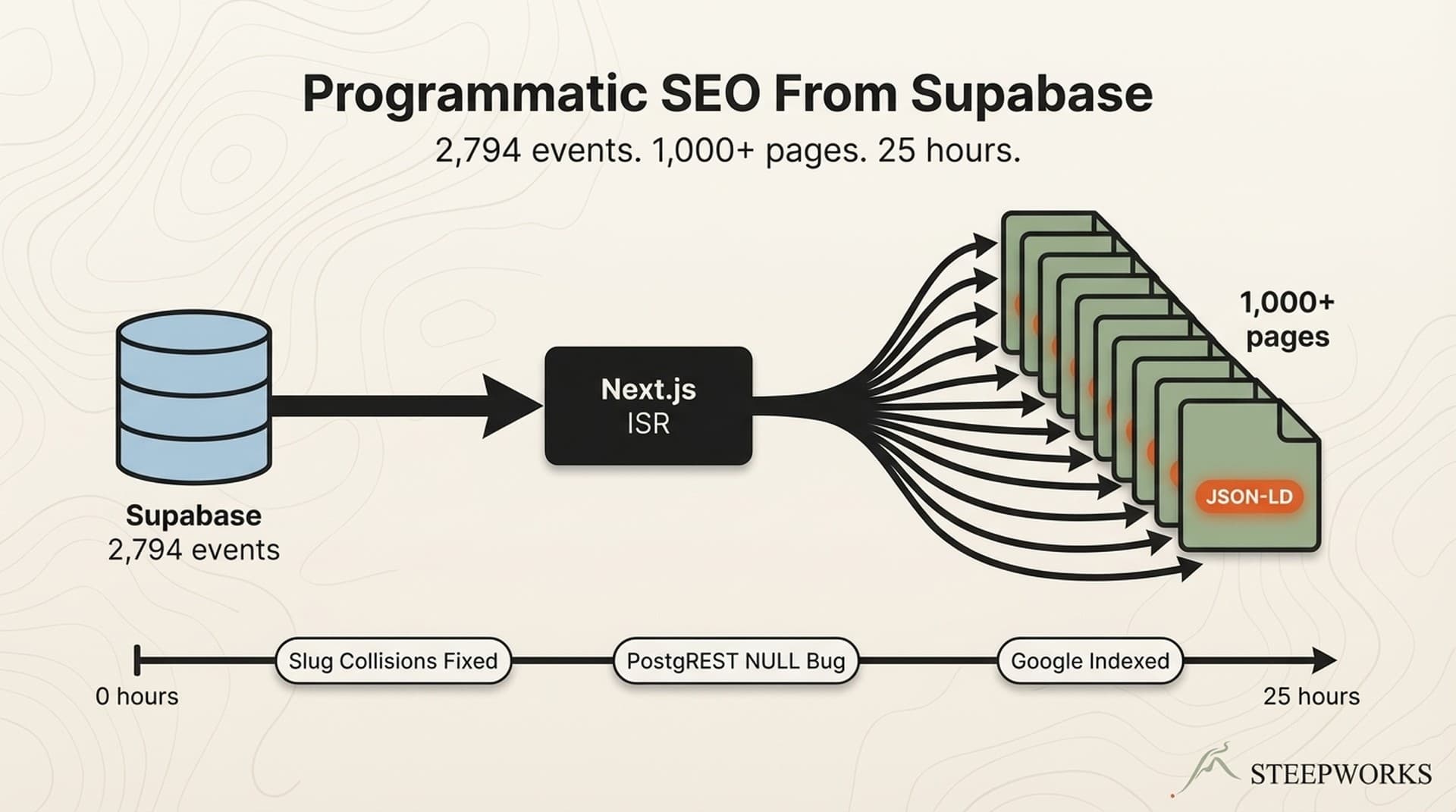
The Architecture — Supabase to Google in Four Layers
The stack: Supabase (data) -> Next.js App Router (rendering) -> Vercel (deploy + edge cache) -> Google (index).
The Data Layer
The events table carries everything a page needs: title, summary, content, venue, address, dates, times, type, location area, age range, cost type, cost amount, image URL, and slug.
Slug generation runs via SQL trigger on insert: {slugified-title}-{YYYY-MM-DD}, falling back to {title}-{id} when dates are missing. This is where the first surprise hit — 55 collision groups emerged from recurring events with the same title and date. A weekly "Story Time at Enoch Pratt" generates an identical slug every Saturday. The trigger now detects collisions and appends the database ID, but that wasn't in the original build.
Why Supabase? PostgREST gives the frontend a REST API with zero backend code. Row-level security separates the admin pipeline from the public read layer. A baltimore_events view exposes only approved events to the site.
One gotcha cost me half a day: PostgREST's neq filter silently excludes NULL values. When I filtered for urgency=neq.expired, every event with a NULL urgency field vanished. 63+ future events, gone from every page on BmoreFamilies.com. More on that in the failures section.
The Rendering Layer — Next.js ISR
One dynamic route handles all event pages: /events/[slug]/page.tsx. One template, 1,000+ pages.
generateStaticParams() fetches all slugs at build time. ISR with revalidate = 3600 regenerates pages hourly without a full site rebuild.
Why ISR? Events change weekly — new ones arrive, old ones expire. Full static builds would rebuild all 1,000+ pages for any single change. Pure SSR would be slow for crawlers. ISR gives static HTML for Google with hourly freshness for users.
Any event page on BmoreFamilies.com is rendered this way — bmorefamilies.com/events/polar-bear-plunge-2026-01-25 is one example. Static HTML, Vercel's edge, regenerated every hour.
What Makes Each Page Worth Indexing
If you've lived through Google's March 2024 "scaled content abuse" update, you should flinch at "1,000 database-driven pages." I did too.
But Google doesn't care how a page was made. They care whether it answers the query better than what already exists. Their helpful content guidelines are explicit: the standard is value to the reader, not production method.
What Goes on Each Page
Here's what a single event page on BmoreFamilies.com contains:
Dynamic metadata. Title under 60 characters: {Event Title} | {Venue}. Description under 160 characters with date, venue, cost, and a call-to-action. These are composed from actual event fields — different titles and descriptions on every page.
JSON-LD Event schema. Valid Event structured data with name, startDate, endDate, location (venue name + address), and offers. The URL points to the BmoreFamilies.com page, not the external source. That's a deliberate canonical claim — the page adds classification and context the source doesn't have.
BreadcrumbList schema. Home > Calendar > Event Type > Event Title. Visible breadcrumbs plus JSON-LD for rich results.
Content blocks. Full event description (unique per event), venue details with address, cost badge, age range indicator, recurring schedule flag.
Related events. Up to 6, ranked by relevance: same venue first, then same type, then same weekend. Each link passes equity and gives the crawler more paths. This is internal linking between content nodes, not a "more posts" widget.
Newsletter cross-link. If the event was featured in a BmoreFamilies newsletter issue, the page links to that issue. The newsletter archive links back. Bidirectional internal linking between content types.
Past event handling. This is a detail I haven't seen covered elsewhere. Events older than 6 months get noindex — they leave Google naturally. Events within 6 months show a "This event has passed" banner with similar upcoming events. Someone searching for last month's event finds the page, sees upcoming alternatives. Long-tail value preserved, index kept clean.
The Side-by-Side
A typical thin database-generated page:
Title: "Event in Baltimore" Body: "Check out this event in Baltimore. Click here for details." No schema. No related content. No internal links. Identical template, one variable swapped. Google will deindex it.
What BmoreFamilies.com produces: (See also: quality gate)
Title: "Polar Bear Plunge 2026 | Maryland State Police | Sandy Point State Park" (See also: anti slop) Body: Full event description, venue with street address, date and time, cost badge ("FREE"), age range ("All Ages"), recurring schedule indicator, 6 related events, cross-links to category hubs (Outdoor, Anne Arundel County, All Ages), newsletter mention, subscribe CTA. Schema: JSON-LD Event + BreadcrumbList. Internal links: 6 related events, 4 category cross-links, newsletter cross-link, calendar link, homepage.
One wastes the crawler's time. The other answers the search query better than the original source, because it adds classification, context, related discovery, and structured data the source page doesn't have.
See it live: bmorefamilies.com/events/free shows how free events aggregate into a hub page, not a thin listing.
Technical Compliance
- Each page: unique combination of title, venue, date, description, and related events
- No two pages have identical content
- External links use
rel="nofollow noopener noreferrer" - Self-referencing canonical URLs — each page claims itself as canonical because the aggregation adds value the source doesn't have
- Old events noindexed after 6 months
Google's crawler can verify all of this programmatically. Unique titles, unique descriptions, unique JSON-LD payloads, unique internal link graphs. The uniqueness is machine-readable, not just human-visible.
Category Hub Pages — Where the Real Traffic Lives
Individual event pages capture ultra-specific long-tail searches. Useful, but the traffic compounds when you add category hub pages targeting medium-tail keywords — the queries with actual monthly volume.
BmoreFamilies.com has 22+ hub pages across four dimensions:
By type (10 pages). /events/type/museum, /events/type/outdoor, and 8 others. Target: "museums for kids in Baltimore," "outdoor activities for families Baltimore."
By area (5 pages). /events/area/baltimore-city, /events/area/howard-county, and 3 others. Target: "things to do with kids in Howard County."
By age (7 pages). /events/age/toddler, /events/age/elementary, and 5 others. Target: "toddler activities Baltimore." (course vs done-for-you comparison)
By intent (2 pages). /events/free and /events/this-weekend. Highest-intent queries: "free things to do with kids Baltimore" and "family events this weekend." (DIY vs professional setup)
Each hub has hand-written intro copy with local context. JSON-LD ItemList schema. Cross-links to other categories. Dynamic event counts that update hourly via ISR. (Claude Code alternatives comparison)
The internal link graph matters here. Hub pages link down to individual events. Events link up to hubs via breadcrumbs and category pills. Calendar links to all hubs. Homepage links to calendar. Every page reachable from every other page within 3 clicks. That's how Google sees 1,000+ pages as a coherent site rather than a link farm. (when to implement Claude Code)
Sitemap and Indexing — Briefly
I'll keep this short because the implementation is standard, but two things are worth noting. (what professional setup includes)
The sitemap is generated dynamically from Supabase — a sitemap.ts file fetches slugs and generates URLs at request time. Hub pages get priority: 0.7, active events 0.6, past events 0.3. You can inspect it: bmorefamilies.com/sitemap.xml. It went from 8 URLs to 1,000+ in a single deploy. (why Claude Code feels too hard)
The thing I underestimated: Google is cautious with new domains claiming large page counts. Initial crawl took days, not hours. Crawl rate only accelerated after external backlinks arrived. More on why that matters in the results section. (Knowledge OS explained)
What Broke — Failures and Fixes in the First 30 Days
Everything above sounds clean. It wasn't.
Slug collisions on recurring events. "Story Time at Enoch Pratt" every Saturday? Same slug. The SQL trigger had no collision detection at launch. 55 collision groups emerged before I added a migration that detects duplicates and appends the database ID. (context engineering deep dive)
PostgREST NULL filtering — the worst one. urgency=neq.expired silently excluded all events with NULL urgency. 63+ future events vanished from BmoreFamilies.com. The site looked half-empty for two days before I traced it. Fix: or(urgency.neq.expired,urgency.is.null). PostgREST doesn't warn you about this behavior. If you're using Supabase with PostgREST filters, check your NULL handling now. (how to evaluate a consultant)
Duplicate event cards. Same event scraped from multiple sources created duplicate rows. "Polar Bear Plunge" appeared twice in related events — once from the Maryland State Police site, once from the Sandy Point park calendar. Fix: composite dedup key on title + venue + date in the fetch layer.
Stale data after ISR window. Cancelled events didn't update until the next hourly regeneration. For a directory, an hour of staleness is fine — users click through to the source URL for the freshest info. For a ticketing site processing payments, it wouldn't be.
Indexing lag. Valid sitemap with 1,000+ URLs, and Google still took weeks to crawl beyond the homepage. Expected for a new domain with no backlinks, but patience is hard when you're watching Search Console. External backlinks — mentions in local parenting communities, newsletter cross-promotions — were the crawl-rate accelerator. Not just a ranking factor, but the thing that got Google to take the sitemap seriously. No shortcut here.
Results at 4 Weeks, and What I'd Change
It's early. Four weeks is not enough time to claim organic traffic results from programmatic SEO, and I'm not going to pretend otherwise. Comparable launches — like the Omnius case study that documented 3,035% growth — took 10 months. Here's what I can say now.
What's live: 1,000+ event pages and 22 category hub pages on BmoreFamilies.com. Visit any of them. They're real. Sitemap went from 8 to 1,000+ URLs. 313+ sources feed new events weekly, each auto-slugged and in the sitemap within an hour. Event JSON-LD on every event page, BreadcrumbList on every page, ItemList on all 22 hubs.
What Search Console shows so far: Google is indexing progressively. Long-tail queries are appearing in impressions — specific event names, "free [activity] Baltimore" patterns, venue-based searches. The hub pages (free events, this weekend) captured high-intent searches first, which makes sense — they have more internal links, more content depth, and target higher-volume queries than any individual event page.
What I'd do differently:
I'd launch hub pages first. They showed traction faster than individual event pages, and in hindsight that's obvious — medium-competition keywords with 20+ internal links beat ultra-long-tail pages with 6 links. If I rebuilt this, I'd ship 20 hub pages on day one and backfill individual pages behind them.
I'd also invest in backlinks from day one instead of treating them as a "later" problem. 1,000 pages in a sitemap don't matter if Google doesn't trust the domain enough to crawl them. I assumed a valid sitemap plus good structured data would be enough to get crawling started. It wasn't.
The one thing I'm still unsure about: whether SearchAction schema (the JSON-LD that enables Google's sitelinks search box) would have accelerated indexing. I added it late. Might be placebo. Might matter. I'll have better data in another month.
Building systems like this — turning structured data into content operations that generate pages without per-page effort — is the kind of work we do at STEEPWORKS. If you're sitting on a database that should be generating pages, we should talk.
When This Pattern Does and Doesn't Apply
I built this for a local events directory, but the architecture maps to any structured dataset. Zapier runs 50,000+ integration pages. SaaS comparison pages ("[Product] vs. [Competitor]") work the same way. Template galleries, use-case pages, marketplace listings — same slug pattern, same hub-and-spoke linking.
The pattern works when each page answers a genuinely different query, your data is rich enough to produce a page worth reading (not one sentence and a link), and new records keep flowing in. It doesn't work on static datasets, thin data, or pages where swapping one variable doesn't change the advice.
The line between directory and spam farm is the value each page adds beyond what Google already knows. If your page aggregates 313 sources into one schema-marked, internally-linked answer for "free museum days Baltimore this weekend" — that's search working correctly.
Go see it: BmoreFamilies.com.